Fault Handling Techniques
This article describes some of the techniques that are used in fault handling software design. A typical fault handling state transition diagram is described in detail. The article also covers several fault detection and isolation techniques.
Fault Handling Lifecycle
The following figure describes the fault handling lifecycle of an active unit in a redundancy pair.
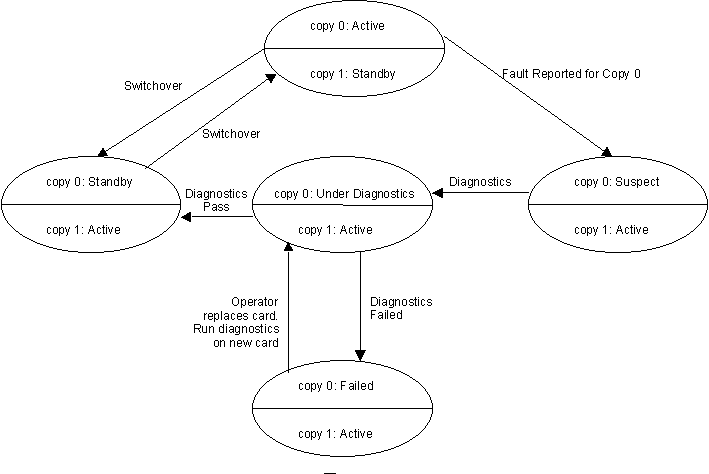
- Assume that the system is running with copy-0 as active unit and copy-1 as standby.
- When the copy-0 fails, copy-1 will detect the fault by any of the fault detection mechanisms.
- At this point, copy-1 takes over from copy-0 and becomes active. The state of copy-0 is marked suspect, pending diagnostics.
- The system raises an alarm, notifying the operator that the system is working in a non-redundant configuration.
- Diagnostics are scheduled on copy-0. This includes power-on diagnostics and hardware interface diagnostics.
- If the diagnostics on copy-0 pass, copy-0 is brought in-service as standby unit. If the diagnostics fail, copy-0 is marked failed and the operator is notified about the failed card.
- The operator replaces the failed card and commands the system to bring the card in-service.
- The system schedules diagnostics on the new card to ascertain that the card is healthy.
- Once the diagnostics pass, copy-0 is marked standby.
- The copy-0 now starts monitoring the health of copy-1 which is currently the active copy.
- The system clears the non-redundant configuration alarm as redundancy has been restored.
- The operator can restore the original configuration by switching over the two copies.
Fault Detection and Isolation
Fault Detection
One of the most important aspects of fault handling is detecting a fault immediately and isolating it to the appropriate unit as quickly as possible. Here are some of the commonly used fault detection mechanisms.
- Sanity Monitoring: A unit monitors the health of another unit by expecting periodic health messages. The unit that is being monitored should check its sanity and send the periodic health update to the monitoring unit. The monitoring unit will report a fault if more than a specified number of successive health messages are lost.
- Watchdog Monitoring: This is the hardware based monitoring technique to detect hanging hardware or software modules. The system is configured with a hardware timer that should be never allowed to timeout. The software periodically restarts the timer under normal conditions. If the software goes in an infinite loop or a hardware module gets stuck, the watchdog timer would go off. This typically leads to a hardware reset of the unit and a hardware signal to the mate unit.
- Protocol Faults: If a unit fails, all the units that are in communication with this unit will encounter protocol faults. The protocol faults are inherently fuzzy in nature as they may be due to a failure of any unit in the path from the source to destination. Thus further isolation is required to identify the faulty unit.
- In-service Diagnostics: Sometimes the hardware modules are so designed that they allow simple diagnostic checks even in the in-service state. These checks are non-destructive in nature so they do not interfere with the normal functioning of the card. For example, on a digital trunk card, in-service diagnostics may be performed on idle channels. If a diagnostic check fails, a fault trigger is raised.
- Transient Leaky Bucket Counters: When
the hardware is in operation, many transient faults may be detected by the
system. Transient faults are typically handled by incrementing a leaky
bucket counter. If the leaky bucket counter overflows, a fault trigger
is raised. The following are few examples of transient faults.
- Spurious interrupts: If the interrupt service routine gets called but no device is found to have raised any interrupt, only a leaky bucket counter is incremented. The hardware unit is suspected only if the leaky bucket counter overflows due to spurious interrupts happening repeatedly in a short interval.
- Spurious fault triggers: As we discussed in the fault handling lifecycle, when a fault trigger is generated the hardware unit is suspected and diagnostics are run. If the diagnostics pass, the unit is brought in and a leaky bucket counter is incremented. If this sequence repeats too often, the hardware unit may be actually faulty but the diagnostics are not exhaustive enough to detect the hardware fault.
- Killer trunks: Due to events like lightening, rains etc. digital trunks might frequently generate fault triggers but may come back in-service. If this happens too frequently, the digital trunk is marked as a "killer trunk" and is taken out of service. This is done to avoid the system getting overloaded with transient fault processing.
Fault Isolation
If a unit is actually faulty, many fault triggers will be generated for that unit. The main objective of fault isolation is to correlate the fault triggers and identify the faulty unit. If fault triggers are fuzzy in nature, the isolation procedure involves interrogating the health of several units. For example, if protocol fault is the only fault reported, all the units in the path from source to destination are probed for health.