Reliability and availability basics
Reliable functioning of embedded systems is of paramount concern to the billions of users that depend on these systems everyday. Unfortunately most embedded systems still fall short of users expectation of reliability.
In this article we will discuss basic techniques for measuring and improving reliability of computer systems. The following topics are discussed:
Failure characteristics
Hardware failures
Hardware failures are typically characterized by a bath tub curve. An example curve is shown below. The chance of a hardware failure is high during the initial life of the module. The failure rate during the rated useful life of the product is fairly low. Once the end of the life is reached, failure rate of modules increases again.
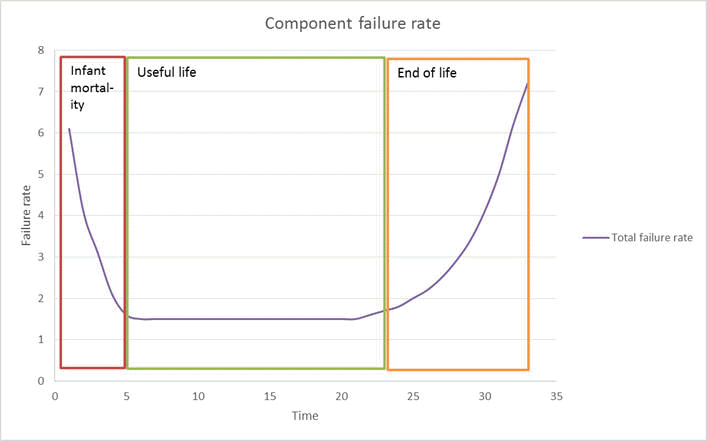
Hardware failures during a products life can be attributed to the following causes:
- Design failures: This class of failures take place due to inherent design flaws in the system. In a well-designed system this class of failures should make a very small contribution to the total number of failures.
- Infant Mortality: This class of failures cause newly manufactured hardware to fail. This type of failures can be attributed to manufacturing problems like poor soldering, leaking capacitor etc. These failures should not be present in systems leaving the factory as these faults will show up in factory system burn in tests.
- Random Failures: Random failures can occur during the entire life of a hardware module. These failures can lead to system failures. Redundancy is provided to recover from this class of failures.
- Wear Out: Once a hardware module has reached the end of its useful life, degradation of component characteristics will cause hardware modules to fail. This type of faults can be weeded out by preventive maintenance and routing of hardware.
The following graph shows the contribution of the different failure modes towards the overall failure rate.
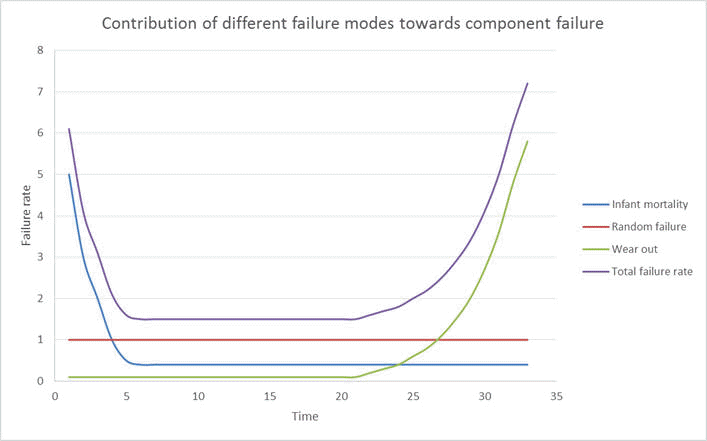
Software failures
Software failures can be characterized by keeping track of software defect density in the system. This number can be obtained by keeping track of historical software defect history. Defect density will depend on the following factors:
- Software process used to develop the design and code (use of peer level design/code reviews, unit testing)
- Complexity of the software
- Size of the software
- Experience of the team developing the software
- Percentage of code reused from a previous stable project
- Rigor and depth of testing before product is shipped.
Defect density is typically measured in number of defects per thousand lines of code (defects/KLOC).
Reliability parameters
MTBF
Mean Time Between Failures (MTBF), as the name suggests, is the average time between failure of hardware modules. It is the average time a manufacturer estimates before a failure occurs in a hardware module.
MTBF for hardware modules can be obtained from the vendor for off-the-shelf hardware modules. MTBF for in-house developed hardware modules is calculated by the hardware team developing the board.
MTBF for software can be determined by simply multiplying the defect rate with KLOCs executed per second.
FITS
FITS is a more intuitive way of representing MTBF. FITS is nothing but the total number of failures of the module in a billion hours (i.e. 1000,000,000 hours).
MTTR
Mean Time To Repair (MTTR), is the time taken to repair a failed hardware module. In an operational system, repair generally means replacing the hardware module. Thus hardware MTTR could be viewed as mean time to replace a failed hardware module. It should be a goal of system designers to allow for a high MTTR value and still achieve the system reliability goals. You can see from the table below that a low MTTR requirement means high operational cost for the system.
| Estimating the Hardware MTTR | ||
| Where are hardware spares kept? | How is site manned? | Estimated MTTR |
| Onsite | 24 hours a day | 30 minutes |
| Onsite | Operator is on call 24 hours a day | 2 hours |
| Onsite | Regular working hours on week days as well as weekends and holidays | 14 hours |
| Onsite | Regular working hours on week days only | 3 days |
| Offsite. Shipped by courier when fault condition is encountered. | Operator paged by system when a fault is detected. | 1 week |
| Offsite. Maintained in an operator controlled warehouse | System is remotely located. Operator needs to be flown in to replace the hardware. | 2 week |
MTTR for a software module can be computed as the time taken to reboot after a software fault is detected. Thus software MTTR could be viewed as the mean time to reboot after a software fault has been detected. The goal of system designers should be to keep the software MTTR as low as possible. MTTR for software depends on several factors:
- Software fault tolerance techniques used
- OS selected (does the OS allow independent application reboot?)
- Code image downloading techniques
| Estimating Software MTTR | ||
| Software fault recovery mechanism | Software reboot mechanism on fault detection | Estimate MTTR |
| Software failure is detected by watchdog and/or health messages | Processor automatically reboots from a ROM resident image. | 30 seconds |
| Software failure is detected by watchdog and/or health messages | Processor automatically restarts the offending tasks, without needing an operating system reboot | 30 seconds |
| Software failure is detected by watchdog and/or health messages | Processor automatically reboots and the operating system reboots from disk image and restarts applications | 3 minutes |
| Software failure is detected by watchdog and/or health messages | Processor automatically reboots and the operating system and application images have to be download from another machine | 10 minutes |
| Software failure detection is not supported. | Manually operator reboot is required. | 30 minutes to 2 weeks (software MTTR is same as hardware MTTR) |
Availability
Availability of the module is the percentage of time when system is operational. Availability of a hardware/software module can be obtained by the formula given below.
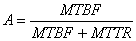
Availability is typically specified in nines notation. For example 3-nines availability corresponds to 99.9% availability. A 5-nines availability corresponds to 99.999% availability.
Downtime
Downtime per year is a more intuitive way of understanding the availability. The table below compares the availability and the corresponding downtime.
| Availability | Downtime |
| 90% (1-nine) | 36.5 days/year |
| 99% (2-nines) | 3.65 days/year |
| 99.9% (3-nines) | 8.76 hours/year |
| 99.99% (4-nines) | 52 minutes/year |
| 99.999% (5-nines) | 5 minutes/year |
| 99.9999% (6-nines) | 31 seconds/year ! |
Explore more
- System reliability and availability: Techniques for calculating system availability from the availability information for its components
- Hardware fault tolerance: Covers several techniques that are used to minimize the impact of hardware faults.
- Fault handling techniques: Describes fault handling state transitions and fault isolation techniques
- Hardware diagnostics: Hardware diagnostics and power on self tests are described here. In service fault diagnostics are also covered.
- Software fault tolerance: Techniques that can be used to limit the impact of software faults (bugs) on system performance